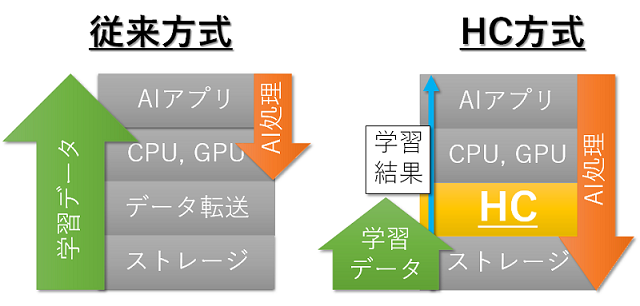
Hybrid Computing (HC) とは tonoi が開発する Hybrid Computing (HC) は、ストレージ上の大容量データをクラウドに転送するのではなく、大容量データが存在するストレージに対しコンパクトな演算処理コードを転送し実行する仕組みです。大容量データを保管するストレージに HC 機能を導入すると複数のメリットがあります。
- ストレージ自身が持つ高度な演算力をデータ転送よりも演算処理に多く割り当てることが可能となる
- 複数台のストレージ構成に HC 機能を導入した場合、それぞれのストレージに対し個別の処理を行わせることが可能であり分散処理による負荷分散が可能
- 巨大なデータがストレージからクラウドに移動せず、末端のストレージ上すなわち巨大データに物理的にも一番近い箇所で演算処理が行われるため、データ自体が電気的にも移動する距離が最短になる。このためここでもデータ転送量が削減されレスポンスが向上
データ転送の問題
クラウドやAI技術の進歩で巨大データが必要になった現代、データ転送速度不足の問題が随所で発生しています。理論的に、データ転送速度の進化を表すギルダーの法則はムーアの法則によるデータ量の増加よりも遅く、10年間で相対速度が1/10になります。
このデータ転送速度不足の問題は、時代の経過とともに重大な課題となり顕在化してきています。
$ データ量: \displaystyle \lim_{ x \to \infty } n \times \log n > 転送速度: 2^{x/1.5} \times 3
, $
$ \scriptsize{
フィボナッチ数: n = \frac{ \phi ^ x - (-\phi)^{-x} }{ \sqrt{5} } , \
黄金比: \phi = \frac{ 1 + \sqrt{ 5 } }{2}
}$
HC によるパラダイムシフト (シーケンシャルとランダム)
初期のパソコンはカセットテープからシーケンシャルにアプリやデータを読み込んでいました。フロッピーディスクの出現でランダムアクセスが可能になり膨大なデータが扱えるようになりました。
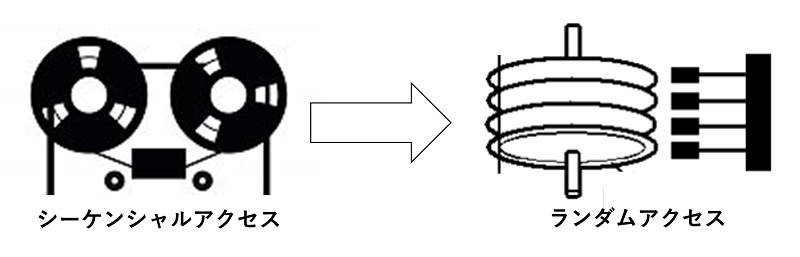
現代にあてはめると、天気予報や検索エンジンなどのビッグデータはランダムアクセスですが、AIの学習は大きなデータを頭から読みだしているシーケンシャルアクセスになっています。ビッグデータは Map & Reduce など解析手法が確立され膨大なデータを小単位に分割し高効率に処理しておりますが、AIの学習に使われる Deep Learning は個々のデータが大きくデータ転送速度が問題になっています。データ転送の問題は速度だけでなくランダムとシーケンシャルの違いも関係しているのです。
クラウド上、エッジコンピューティング、IoT などに複数の HC を導入したストレージを設置することで、収集データが発生しているその場所で HC から送られた演算処理が収集データに適用されることになります。それはまるでアプリからお互いに離れて置かれた多様なデータにランダムアクセスができるように見えるということになります。
HC はテープからディスクへのパラダイムシフトと同じように、クラウドから転送速度不足に悩むことなく世界に広がる膨大なデータが扱える世界を実現します。
HC の仕組み
HC はユーザーが開発したコード ( HC アプリ ) が “Proxy” サービスを通してデータにアクセスすることで、演算能力を持つ HC 対応ストレージ上の “Stub” によって自動的に分散実行されます。
“Proxy”
複数の HC 対応ストレージをまとめて管理し、HC アプリへ公開するゲートウェイサービス
HC アプリは “Proxy” を通してデータアクセスを行うロジックを HC 対応ストレージにロジックを自動配信し、処理結果のみを受け取る。
“Stub”
エッジ側のストレージを “Proxy” 側に接続するサービス
HC 対応ストレージは “Proxy” からロジックを受け取り、ストレージ内のデータを処理して結果を “Proxy” へ返す。
HC に関する特許: 特願 2018-089022、2018-159325
“Proxy"と"Stub"を組み合わせた分散データ処理基盤を Hybrid Computer と呼称します。
動作デモ
25Tのラットの病理画像データベースからマッチするものを探す処理を、従来型の n層アーキテクチャと HC で比較しています。HC では病理画像があるストレージ機器の内部でマッチを行うためデータ転送が削減され高速化されています。
HC がもつ六つの特長
組み込み対応
様々な CPU / GPU / FPGA などに同一のソースコードで対応可能
帯域削減
ロジックをデータの場所に送ることでデータ転送を削減
電力削減
データ転送量を削減することで消費電力削減
対象処理に最適な CPU / GPU / FPGA などを利用
親和性
オブジェクトストレージと互換性があるため、既存ハードウェア・サービスとの親和性が高い
高度化
分散するエッジを仮想化しクラウド上にあるかのように見せかけ開発・セキュリティ・運用を集中
遅延削減
エッジコンピューティングの特徴であるリアルタイム性を実現
HC がもたらす効果
DevOps
クラウドが一般的になり、運用しながらアップデートを繰り返す DevOps も一般的になってきました。エッジコンピューティングでは、エッジ側のアプリのバージョン管理が必要です。HCではエッジのストレージは仮想化されクラウド上のメンテナンスだけで済みます。
長期運用
工場などで利用されるシステムは専用のコンピュータでサービスを長期運用していくと機材の更新が必要になります。
ハードウェアや OS 、アプリケーションが廃番などで入手不可能になり代替品もなく旧式となった機材を使い続けることになり維持が問題となります。
HC はバージョン違いやアーキテクチャの違いなど様々な差異を吸収できるため、最新の汎用品で置き換えることが容易です。
これにより、サービスを止めることなく、最新のハードウェアの機能・性能を利用しながら従来通りのサービスを運用し続けることができます。
開発リソース
HC のアプリ開発にはPythonや様々な AI 用言語が利用可能です。
開発者は新規ライブラリの習得やハードウェアごとの特性を考慮することなく自分の作るべきサービスやアプリ開発に注力できます。
これにより、開発効率の向上や問題修正までの時間短縮が計れると同時に、人材採用や教育に関してのコストも下げられることが期待できます。
低消費電力・低転送帯域
HC では大きなデータを転送するのではなく小さなロジックを転送し、結果を送ります。これにより転送に必要なネットワーク帯域・消費電力を遡源できます。
HC が実現する未来
- 病理画像解析における高画素画像の高速処理とプライバシー向上
- リテールにおける軽量な商品追跡
- 工場のライン検査の集中管理とリアルタイム性
- 防犯カメラ動画のプライバシーを保った商利用
- 各地に点在するビデオライブラリーの軽量なリモート検索
FAQ
Q: エッジコンピューティングとの違い
A: 一般的なエッジコンピューティングは仮想マシン ( Virtual Machine ) による OS 単位での分散、Docker などのコンテナによるアプリ単位での分散を指します。HC はアプリの中の大容量データを処理するロジックのみを自動分散させ、アプリ自体はクラウド上で集中動作する点が異なります。
エッジコンピューティングでしばしば問題になる分散している事による管理の難しさも HC は集中管理が可能ですのでHCの高い信頼性を保障することで DevOps をエッジコンピューティングのように実現することが可能です。
Q: 組み込み機器ですべて作り込めばもっと高速化できる
A: 専用に組み込みで作り込んだ場合に比べ、15%程度のパフォーマンス低下を想定しています。
HC はクラウド上でのロジック変更がエッジへ自動的に反映されるため、クラウド上での集中管理が可能になります。
ロジック変更に手間がかかり機材ごとに入れ替える処理が必要な組み込み機器に比べ自由度が高くメンテナンスが容易であります。これは DevOps に有利となります。
Q: より高速なハードウェアを用意すれば大容量データを扱える
A: ムーアの法則とギルダーの法則の差により、10年でデータの相対転送速度が 1/10 に低下します。
また、より大規模なハードウェアを使用するスケールアップ指向では複数のデータ通信が同時に発生し、その交差がボトルネックとなります。HC は IoT やエッジコンピューティングなどより安価で多数のハードウェアに分散させるスケールアウト指向のアプリ技術であり、同じような高性能のハードウェアを利用すればHCによってさらに大容量データが扱えます。
Q: そんな大容量データは現場で使用していない
A: 工場のラインでは AI 学習用の検査機器画像データは一部だけを取得し研究室で学習させており、多くの画像データは利用されることなく廃棄されています。
今まで捨てていたデータを HC 対応ストレージで分散AI学習させることで新しい自動化が可能となります。
IoT やエッジコンピューティング上で学習する手法は Google では Federated Learning、IBM では Distributed Deep Learning と呼び研究されています。
Q: 新技術の習得に時間をかけられない
A: HC はエッジ側に置かれている様々なハードウェアをその違いを考慮することなく同じように扱えます。分散処理に向けた各種ライブラリを習得することなく分散システムを使い始めることができます。
また、アプリ開発には開発効率が良く費用対効果も高く保守性も高いプログラミングが可能な Python や様々な AI 用言語が利用できます。
Special Thanks 東京理科大学 理窓ビジネス同友会 白鳥 考生様